
COSC 6373: Computer Vision In-Class Assignment 2
Image classification with Convolutional Neural Networks and Transfer Learning
This note is an assignment from COSC 6373 assignment.
Goal
Using transfer learning technique on a pre-trained ResNet50 CNN model to perform classification for recognizing images of horses and camels. Tensorflow framework will be utilized to implement the task.
Introduction
ResNet50
ResNet is a specific type of CNN means Residual Network which forms networks by stacking residual blocks. ResNet50 is a CNN with 50 layers(48 convolutional layers, one MaxPool layer, and one average pool layer). https://datagen.tech/guides/computer-vision/resnet-50/ https://www.tensorflow.org/api_docs/python/tf/keras/applications/resnet50/ResNet50
ImageNet
ImageNet is a large scale hieararchical image database, contains more than 1.2 millions images of 1000 classes https://www.image-net.org/ The ResNet50 model was pre-trained on ImageNet, so we can use the pre-trained weights.
Transfer Learning
Tansfer leanring means transferring the knowledge of a pre-trained model to perform a new task. The pre-trained model is usually trained on a large scale dataset like the ImageNet for image-classification task. It is a generic model and the learned feature maps can be very useful. To train such a model from scratch requires lots of data, time, and resources. Thus, it is intuitive that using the feature extraction ability of the pretrained model to perform a new classification task on a small scale dataset.
Experiment
Import the lib, in this task, tensorflow framework was used
1
2
3
4
5
6
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
import seaborn as sns
from google.colab import files
Data Preprocessing
Data Download
Load Dataset from google drive, and unzip the zip file to current content
1
2
3
4
5
from google.colab import drive
drive.mount('/content/drive')
!unzip -q '/content/drive/MyDrive/Datasets/archive.zip'
train_dir = '/content/train';
test_dir = '/content/test';
1
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
Input pipeline using Tensorflow Keras
References: https://www.tensorflow.org/tutorials/images/transfer_learning https://keras.io/guides/transfer_learning/
Load dataset using tensorflow utils and create tf.data.Dataset object. In order to input the image to the ResNet50 model, the image size has to be 224 by 224. The resize process can be done during dataloader process via Keras.utils.image_dataset_from_directory. https://www.tensorflow.org/api_docs/python/tf/keras/utils/image_dataset_from_directory
The batch size was set to 32, image size was resized to 224 by 224.
The dataset do not contains validation data set, thus, 20% of data will be taken from the train data. For training and validation dataset, set shuffle = True will shuffle the data. For test data set shuffle = False to better evaluate the result.
In the end, there was 10 batches for training data, 2 batches for validation, and 2 batches for testing.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#set batch size to 32, but why 32?
BATCH_SIZE = 32
#the image size for ResNet50 model input should be 224*224, resize it
IMG_SIZE = (224, 224)
#for training and validation we set shuffle = True
dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
#for test we set shuffle = False to better evaluate the result
test_dataset = tf.keras.utils.image_dataset_from_directory(test_dir,
shuffle=False,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
# create a validation dataset from train_datase
val_batches = tf.data.experimental.cardinality(dataset)
validation_dataset = dataset.take(val_batches // 5)
train_dataset = dataset.skip(val_batches // 5)
print('Number of dataset batches: %d' % tf.data.experimental.cardinality(dataset))
print('Number of train batches: %d' % tf.data.experimental.cardinality(train_dataset))
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
1
2
3
4
5
6
Found 360 files belonging to 2 classes.
Found 40 files belonging to 2 classes.
Number of dataset batches: 12
Number of train batches: 10
Number of validation batches: 2
Number of test batches: 2
Show the 40 test_dataset images and labels.
A question for this data loader part is why the original image contains only the object but no background, after the data loader, each image contains a background. And the backgroud is only in the bounding box area. Some image contains a large area of white space, will it affect the learn of the model?
1
2
3
4
5
6
7
8
9
10
11
12
class_names = test_dataset.class_names
print(class_names)
plt.figure(figsize=(10, 10))
for images, labels in test_dataset.take(-1):
#print(len(images))
for i in range(len(images)):
plt.subplot(5, 8, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
#print(images[i].shape)
1
2
3
4
5
['camel', 'horse']
<ipython-input-4-b987f42f6524>:8: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.
plt.subplot(5, 8, i + 1)

Questions for the data loader
- The original image contains no background, but after loading through tf.keras.utils.image_dataset_from_directory, the background shows.
After more research and communicate with classmate, the reason is the dataset actually contains background, but they use alpha channel to block the background, when loading to the tf.data.Dataset the image was converted to RGB, the alpha channel was removed, so the image is shown with the background.
Take train/camel/10.png as an example. It shows that the image contains only the camel itself.
Loaded using PIL
1
2
3
4
5
from PIL import Image
camel = Image.open('/content/train/camel/10.png')
plt.imshow(camel)
plt.axis('off')
plt.show()

Convert to RGB, the background is shown.
1
2
3
4
camel = Image.open('/content/train/camel/10.png').convert('RGB')
plt.imshow(camel)
plt.axis('off')
plt.show()

- Why only the bounding box area contains background, the rest area of the image are all white?
This is because, the dataset itself already pre-process the image to square image, it padding a rectangle image with white pixels to a square image.
- Will the white part of the image decrease the learning ability of the model and affect the performance?
As for my classmate, he said, it depends on the model, ResNet is a very deep model, which can well extract local features, so in our case it would work well, however, for some shallow model, it would be bad.
Configure the dataset for performance
Prefetching is a transformation step, which overlaps the preprocessing and model execution of a training step to enable better performance to prevent I/O blocking by using a background thread and an internal buffer to prefetch loaded images from the disk before they are used. https://www.tensorflow.org/guide/data_performance
1
2
3
4
5
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
Use data augmentation
The camels and horses dataset only contains 400 images, so a data augmentation process may useful to train a more generic model and avoid overfitting. Typically, the data augmentation can be seen as sequential layers contains different transformation operation on the image, in the experiment, a random flip on the x axis of the image and a random rotation was applied.
However, during the experiment, the result for the data augmentation seems not correct. Besides, the performance of the model without the data augmentation layers was slightly higher. More detail results will be shown in the end of this report.
1
2
3
4
5
6
7
8
9
10
11
12
13
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

Question for Data Augmentation
Why the result seems not correct like the one in the tutorial? https://www.tensorflow.org/api_docs/python/tf/keras/layers/RandomRotation
Points outside the boundaries of the input are filled according to the given mode (one of {“constant”, “reflect”, “wrap”, “nearest”}). reflect: (d c b a | a b c d | d c b a) The input is extended by reflecting about the edge of the last pixel.
It seems like the empty part after random rotation is filled by reflecting abou the edge of the last pixel. The image contains white space, that’s why it looks weried.
Rescale pixel value
A important step for transfer learning is the input should be processed to meet the expectation of the base model. Each Keras Application expects a specific kind of input preprocessing. For the preprocess_input of ResNet50 will convert the input images from RGB to BGR, then will zero-center each color channel with respect to the ImageNet dataset, without scaling.
At the first trail of the experiment, the preprocess_input was not included, and the result was slightly worse than the model with the preprocess_input. More results will be shown in the end of the report.
1
preprocess_input = tf.keras.applications.resnet50.preprocess_input
Create Base Model
A base model from the ResNet50 model was created which pre-trained on the ImageNet dataset. This base of knowledge will be benifical to classify camels and horses from our specific dataset.
According to the common practice, the features of “bottleneck layer” which is the last layer before the flatten operation are more generality than the top classification layer of the base model. Thus, to do transfer learning, the top classification layer of the base model was removed and the base model was used as a feature extractor.
1
2
3
# Create the base model from ResNet50 using pre-trained weight on ImageNet, exclude the top layer
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.ResNet50(weights = 'imagenet', include_top = False, input_shape = IMG_SHAPE)
The base model which was served as a feature extractor in our case, converts each 2242243 image into a 7x7x2048 block of features.
1
2
3
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print('feature_batch_shape: ', feature_batch.shape)
1
feature_batch_shape: (32, 7, 7, 2048)
Feature Extraction
In this step, the base model will be freezed and to use as a feature extractor, which means the base model is not trainable, the function for the base model is to extract generic features for the later specific classification task. In order to do the classification task, a classifiction layer will be added on top of base model. And will train the top-level classifier on our dataset.
Freeze the Base Model
1
2
3
4
5
#Freeze the base model
base_model.trainable = False
#base model architecture
#noticed that the trainable parameters here was 0 because we set trainable = false, basically freeze the model
base_model.summary()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
Model: "resnet50"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 224, 224, 3 0 []
)]
conv1_pad (ZeroPadding2D) (None, 230, 230, 3) 0 ['input_1[0][0]']
conv1_conv (Conv2D) (None, 112, 112, 64 9472 ['conv1_pad[0][0]']
)
conv1_bn (BatchNormalization) (None, 112, 112, 64 256 ['conv1_conv[0][0]']
)
conv1_relu (Activation) (None, 112, 112, 64 0 ['conv1_bn[0][0]']
)
pool1_pad (ZeroPadding2D) (None, 114, 114, 64 0 ['conv1_relu[0][0]']
)
pool1_pool (MaxPooling2D) (None, 56, 56, 64) 0 ['pool1_pad[0][0]']
conv2_block1_1_conv (Conv2D) (None, 56, 56, 64) 4160 ['pool1_pool[0][0]']
conv2_block1_1_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block1_1_conv[0][0]']
ization)
conv2_block1_1_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block1_1_bn[0][0]']
n)
conv2_block1_2_conv (Conv2D) (None, 56, 56, 64) 36928 ['conv2_block1_1_relu[0][0]']
conv2_block1_2_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block1_2_conv[0][0]']
ization)
conv2_block1_2_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block1_2_bn[0][0]']
n)
conv2_block1_0_conv (Conv2D) (None, 56, 56, 256) 16640 ['pool1_pool[0][0]']
conv2_block1_3_conv (Conv2D) (None, 56, 56, 256) 16640 ['conv2_block1_2_relu[0][0]']
conv2_block1_0_bn (BatchNormal (None, 56, 56, 256) 1024 ['conv2_block1_0_conv[0][0]']
ization)
conv2_block1_3_bn (BatchNormal (None, 56, 56, 256) 1024 ['conv2_block1_3_conv[0][0]']
ization)
conv2_block1_add (Add) (None, 56, 56, 256) 0 ['conv2_block1_0_bn[0][0]',
'conv2_block1_3_bn[0][0]']
conv2_block1_out (Activation) (None, 56, 56, 256) 0 ['conv2_block1_add[0][0]']
conv2_block2_1_conv (Conv2D) (None, 56, 56, 64) 16448 ['conv2_block1_out[0][0]']
conv2_block2_1_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block2_1_conv[0][0]']
ization)
conv2_block2_1_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block2_1_bn[0][0]']
n)
conv2_block2_2_conv (Conv2D) (None, 56, 56, 64) 36928 ['conv2_block2_1_relu[0][0]']
conv2_block2_2_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block2_2_conv[0][0]']
ization)
conv2_block2_2_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block2_2_bn[0][0]']
n)
conv2_block2_3_conv (Conv2D) (None, 56, 56, 256) 16640 ['conv2_block2_2_relu[0][0]']
conv2_block2_3_bn (BatchNormal (None, 56, 56, 256) 1024 ['conv2_block2_3_conv[0][0]']
ization)
conv2_block2_add (Add) (None, 56, 56, 256) 0 ['conv2_block1_out[0][0]',
'conv2_block2_3_bn[0][0]']
conv2_block2_out (Activation) (None, 56, 56, 256) 0 ['conv2_block2_add[0][0]']
conv2_block3_1_conv (Conv2D) (None, 56, 56, 64) 16448 ['conv2_block2_out[0][0]']
conv2_block3_1_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block3_1_conv[0][0]']
ization)
conv2_block3_1_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block3_1_bn[0][0]']
n)
conv2_block3_2_conv (Conv2D) (None, 56, 56, 64) 36928 ['conv2_block3_1_relu[0][0]']
conv2_block3_2_bn (BatchNormal (None, 56, 56, 64) 256 ['conv2_block3_2_conv[0][0]']
ization)
conv2_block3_2_relu (Activatio (None, 56, 56, 64) 0 ['conv2_block3_2_bn[0][0]']
n)
conv2_block3_3_conv (Conv2D) (None, 56, 56, 256) 16640 ['conv2_block3_2_relu[0][0]']
conv2_block3_3_bn (BatchNormal (None, 56, 56, 256) 1024 ['conv2_block3_3_conv[0][0]']
ization)
conv2_block3_add (Add) (None, 56, 56, 256) 0 ['conv2_block2_out[0][0]',
'conv2_block3_3_bn[0][0]']
conv2_block3_out (Activation) (None, 56, 56, 256) 0 ['conv2_block3_add[0][0]']
conv3_block1_1_conv (Conv2D) (None, 28, 28, 128) 32896 ['conv2_block3_out[0][0]']
conv3_block1_1_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block1_1_conv[0][0]']
ization)
conv3_block1_1_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block1_1_bn[0][0]']
n)
conv3_block1_2_conv (Conv2D) (None, 28, 28, 128) 147584 ['conv3_block1_1_relu[0][0]']
conv3_block1_2_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block1_2_conv[0][0]']
ization)
conv3_block1_2_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block1_2_bn[0][0]']
n)
conv3_block1_0_conv (Conv2D) (None, 28, 28, 512) 131584 ['conv2_block3_out[0][0]']
conv3_block1_3_conv (Conv2D) (None, 28, 28, 512) 66048 ['conv3_block1_2_relu[0][0]']
conv3_block1_0_bn (BatchNormal (None, 28, 28, 512) 2048 ['conv3_block1_0_conv[0][0]']
ization)
conv3_block1_3_bn (BatchNormal (None, 28, 28, 512) 2048 ['conv3_block1_3_conv[0][0]']
ization)
conv3_block1_add (Add) (None, 28, 28, 512) 0 ['conv3_block1_0_bn[0][0]',
'conv3_block1_3_bn[0][0]']
conv3_block1_out (Activation) (None, 28, 28, 512) 0 ['conv3_block1_add[0][0]']
conv3_block2_1_conv (Conv2D) (None, 28, 28, 128) 65664 ['conv3_block1_out[0][0]']
conv3_block2_1_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block2_1_conv[0][0]']
ization)
conv3_block2_1_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block2_1_bn[0][0]']
n)
conv3_block2_2_conv (Conv2D) (None, 28, 28, 128) 147584 ['conv3_block2_1_relu[0][0]']
conv3_block2_2_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block2_2_conv[0][0]']
ization)
conv3_block2_2_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block2_2_bn[0][0]']
n)
conv3_block2_3_conv (Conv2D) (None, 28, 28, 512) 66048 ['conv3_block2_2_relu[0][0]']
conv3_block2_3_bn (BatchNormal (None, 28, 28, 512) 2048 ['conv3_block2_3_conv[0][0]']
ization)
conv3_block2_add (Add) (None, 28, 28, 512) 0 ['conv3_block1_out[0][0]',
'conv3_block2_3_bn[0][0]']
conv3_block2_out (Activation) (None, 28, 28, 512) 0 ['conv3_block2_add[0][0]']
conv3_block3_1_conv (Conv2D) (None, 28, 28, 128) 65664 ['conv3_block2_out[0][0]']
conv3_block3_1_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block3_1_conv[0][0]']
ization)
conv3_block3_1_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block3_1_bn[0][0]']
n)
conv3_block3_2_conv (Conv2D) (None, 28, 28, 128) 147584 ['conv3_block3_1_relu[0][0]']
conv3_block3_2_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block3_2_conv[0][0]']
ization)
conv3_block3_2_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block3_2_bn[0][0]']
n)
conv3_block3_3_conv (Conv2D) (None, 28, 28, 512) 66048 ['conv3_block3_2_relu[0][0]']
conv3_block3_3_bn (BatchNormal (None, 28, 28, 512) 2048 ['conv3_block3_3_conv[0][0]']
ization)
conv3_block3_add (Add) (None, 28, 28, 512) 0 ['conv3_block2_out[0][0]',
'conv3_block3_3_bn[0][0]']
conv3_block3_out (Activation) (None, 28, 28, 512) 0 ['conv3_block3_add[0][0]']
conv3_block4_1_conv (Conv2D) (None, 28, 28, 128) 65664 ['conv3_block3_out[0][0]']
conv3_block4_1_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block4_1_conv[0][0]']
ization)
conv3_block4_1_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block4_1_bn[0][0]']
n)
conv3_block4_2_conv (Conv2D) (None, 28, 28, 128) 147584 ['conv3_block4_1_relu[0][0]']
conv3_block4_2_bn (BatchNormal (None, 28, 28, 128) 512 ['conv3_block4_2_conv[0][0]']
ization)
conv3_block4_2_relu (Activatio (None, 28, 28, 128) 0 ['conv3_block4_2_bn[0][0]']
n)
conv3_block4_3_conv (Conv2D) (None, 28, 28, 512) 66048 ['conv3_block4_2_relu[0][0]']
conv3_block4_3_bn (BatchNormal (None, 28, 28, 512) 2048 ['conv3_block4_3_conv[0][0]']
ization)
conv3_block4_add (Add) (None, 28, 28, 512) 0 ['conv3_block3_out[0][0]',
'conv3_block4_3_bn[0][0]']
conv3_block4_out (Activation) (None, 28, 28, 512) 0 ['conv3_block4_add[0][0]']
conv4_block1_1_conv (Conv2D) (None, 14, 14, 256) 131328 ['conv3_block4_out[0][0]']
conv4_block1_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block1_1_conv[0][0]']
ization)
conv4_block1_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block1_1_bn[0][0]']
n)
conv4_block1_2_conv (Conv2D) (None, 14, 14, 256) 590080 ['conv4_block1_1_relu[0][0]']
conv4_block1_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block1_2_conv[0][0]']
ization)
conv4_block1_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block1_2_bn[0][0]']
n)
conv4_block1_0_conv (Conv2D) (None, 14, 14, 1024 525312 ['conv3_block4_out[0][0]']
)
conv4_block1_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block1_2_relu[0][0]']
)
conv4_block1_0_bn (BatchNormal (None, 14, 14, 1024 4096 ['conv4_block1_0_conv[0][0]']
ization) )
conv4_block1_3_bn (BatchNormal (None, 14, 14, 1024 4096 ['conv4_block1_3_conv[0][0]']
ization) )
conv4_block1_add (Add) (None, 14, 14, 1024 0 ['conv4_block1_0_bn[0][0]',
) 'conv4_block1_3_bn[0][0]']
conv4_block1_out (Activation) (None, 14, 14, 1024 0 ['conv4_block1_add[0][0]']
)
conv4_block2_1_conv (Conv2D) (None, 14, 14, 256) 262400 ['conv4_block1_out[0][0]']
conv4_block2_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block2_1_conv[0][0]']
ization)
conv4_block2_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block2_1_bn[0][0]']
n)
conv4_block2_2_conv (Conv2D) (None, 14, 14, 256) 590080 ['conv4_block2_1_relu[0][0]']
conv4_block2_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block2_2_conv[0][0]']
ization)
conv4_block2_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block2_2_bn[0][0]']
n)
conv4_block2_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block2_2_relu[0][0]']
)
conv4_block2_3_bn (BatchNormal (None, 14, 14, 1024 4096 ['conv4_block2_3_conv[0][0]']
ization) )
conv4_block2_add (Add) (None, 14, 14, 1024 0 ['conv4_block1_out[0][0]',
) 'conv4_block2_3_bn[0][0]']
conv4_block2_out (Activation) (None, 14, 14, 1024 0 ['conv4_block2_add[0][0]']
)
conv4_block3_1_conv (Conv2D) (None, 14, 14, 256) 262400 ['conv4_block2_out[0][0]']
conv4_block3_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block3_1_conv[0][0]']
ization)
conv4_block3_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block3_1_bn[0][0]']
n)
conv4_block3_2_conv (Conv2D) (None, 14, 14, 256) 590080 ['conv4_block3_1_relu[0][0]']
conv4_block3_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block3_2_conv[0][0]']
ization)
conv4_block3_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block3_2_bn[0][0]']
n)
conv4_block3_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block3_2_relu[0][0]']
)
conv4_block3_3_bn (BatchNormal (None, 14, 14, 1024 4096 ['conv4_block3_3_conv[0][0]']
ization) )
conv4_block3_add (Add) (None, 14, 14, 1024 0 ['conv4_block2_out[0][0]',
) 'conv4_block3_3_bn[0][0]']
conv4_block3_out (Activation) (None, 14, 14, 1024 0 ['conv4_block3_add[0][0]']
)
conv4_block4_1_conv (Conv2D) (None, 14, 14, 256) 262400 ['conv4_block3_out[0][0]']
conv4_block4_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block4_1_conv[0][0]']
ization)
conv4_block4_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block4_1_bn[0][0]']
n)
conv4_block4_2_conv (Conv2D) (None, 14, 14, 256) 590080 ['conv4_block4_1_relu[0][0]']
conv4_block4_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block4_2_conv[0][0]']
ization)
conv4_block4_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block4_2_bn[0][0]']
n)
conv4_block4_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block4_2_relu[0][0]']
)
conv4_block4_3_bn (BatchNormal (None, 14, 14, 1024 4096 ['conv4_block4_3_conv[0][0]']
ization) )
conv4_block4_add (Add) (None, 14, 14, 1024 0 ['conv4_block3_out[0][0]',
) 'conv4_block4_3_bn[0][0]']
conv4_block4_out (Activation) (None, 14, 14, 1024 0 ['conv4_block4_add[0][0]']
)
conv4_block5_1_conv (Conv2D) (None, 14, 14, 256) 262400 ['conv4_block4_out[0][0]']
conv4_block5_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block5_1_conv[0][0]']
ization)
conv4_block5_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block5_1_bn[0][0]']
n)
conv4_block5_2_conv (Conv2D) (None, 14, 14, 256) 590080 ['conv4_block5_1_relu[0][0]']
conv4_block5_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block5_2_conv[0][0]']
ization)
conv4_block5_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block5_2_bn[0][0]']
n)
conv4_block5_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block5_2_relu[0][0]']
)
conv4_block5_3_bn (BatchNormal (None, 14, 14, 1024 4096 ['conv4_block5_3_conv[0][0]']
ization) )
conv4_block5_add (Add) (None, 14, 14, 1024 0 ['conv4_block4_out[0][0]',
) 'conv4_block5_3_bn[0][0]']
conv4_block5_out (Activation) (None, 14, 14, 1024 0 ['conv4_block5_add[0][0]']
)
conv4_block6_1_conv (Conv2D) (None, 14, 14, 256) 262400 ['conv4_block5_out[0][0]']
conv4_block6_1_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block6_1_conv[0][0]']
ization)
conv4_block6_1_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block6_1_bn[0][0]']
n)
conv4_block6_2_conv (Conv2D) (None, 14, 14, 256) 590080 ['conv4_block6_1_relu[0][0]']
conv4_block6_2_bn (BatchNormal (None, 14, 14, 256) 1024 ['conv4_block6_2_conv[0][0]']
ization)
conv4_block6_2_relu (Activatio (None, 14, 14, 256) 0 ['conv4_block6_2_bn[0][0]']
n)
conv4_block6_3_conv (Conv2D) (None, 14, 14, 1024 263168 ['conv4_block6_2_relu[0][0]']
)
conv4_block6_3_bn (BatchNormal (None, 14, 14, 1024 4096 ['conv4_block6_3_conv[0][0]']
ization) )
conv4_block6_add (Add) (None, 14, 14, 1024 0 ['conv4_block5_out[0][0]',
) 'conv4_block6_3_bn[0][0]']
conv4_block6_out (Activation) (None, 14, 14, 1024 0 ['conv4_block6_add[0][0]']
)
conv5_block1_1_conv (Conv2D) (None, 7, 7, 512) 524800 ['conv4_block6_out[0][0]']
conv5_block1_1_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block1_1_conv[0][0]']
ization)
conv5_block1_1_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block1_1_bn[0][0]']
n)
conv5_block1_2_conv (Conv2D) (None, 7, 7, 512) 2359808 ['conv5_block1_1_relu[0][0]']
conv5_block1_2_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block1_2_conv[0][0]']
ization)
conv5_block1_2_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block1_2_bn[0][0]']
n)
conv5_block1_0_conv (Conv2D) (None, 7, 7, 2048) 2099200 ['conv4_block6_out[0][0]']
conv5_block1_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 ['conv5_block1_2_relu[0][0]']
conv5_block1_0_bn (BatchNormal (None, 7, 7, 2048) 8192 ['conv5_block1_0_conv[0][0]']
ization)
conv5_block1_3_bn (BatchNormal (None, 7, 7, 2048) 8192 ['conv5_block1_3_conv[0][0]']
ization)
conv5_block1_add (Add) (None, 7, 7, 2048) 0 ['conv5_block1_0_bn[0][0]',
'conv5_block1_3_bn[0][0]']
conv5_block1_out (Activation) (None, 7, 7, 2048) 0 ['conv5_block1_add[0][0]']
conv5_block2_1_conv (Conv2D) (None, 7, 7, 512) 1049088 ['conv5_block1_out[0][0]']
conv5_block2_1_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block2_1_conv[0][0]']
ization)
conv5_block2_1_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block2_1_bn[0][0]']
n)
conv5_block2_2_conv (Conv2D) (None, 7, 7, 512) 2359808 ['conv5_block2_1_relu[0][0]']
conv5_block2_2_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block2_2_conv[0][0]']
ization)
conv5_block2_2_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block2_2_bn[0][0]']
n)
conv5_block2_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 ['conv5_block2_2_relu[0][0]']
conv5_block2_3_bn (BatchNormal (None, 7, 7, 2048) 8192 ['conv5_block2_3_conv[0][0]']
ization)
conv5_block2_add (Add) (None, 7, 7, 2048) 0 ['conv5_block1_out[0][0]',
'conv5_block2_3_bn[0][0]']
conv5_block2_out (Activation) (None, 7, 7, 2048) 0 ['conv5_block2_add[0][0]']
conv5_block3_1_conv (Conv2D) (None, 7, 7, 512) 1049088 ['conv5_block2_out[0][0]']
conv5_block3_1_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block3_1_conv[0][0]']
ization)
conv5_block3_1_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block3_1_bn[0][0]']
n)
conv5_block3_2_conv (Conv2D) (None, 7, 7, 512) 2359808 ['conv5_block3_1_relu[0][0]']
conv5_block3_2_bn (BatchNormal (None, 7, 7, 512) 2048 ['conv5_block3_2_conv[0][0]']
ization)
conv5_block3_2_relu (Activatio (None, 7, 7, 512) 0 ['conv5_block3_2_bn[0][0]']
n)
conv5_block3_3_conv (Conv2D) (None, 7, 7, 2048) 1050624 ['conv5_block3_2_relu[0][0]']
conv5_block3_3_bn (BatchNormal (None, 7, 7, 2048) 8192 ['conv5_block3_3_conv[0][0]']
ization)
conv5_block3_add (Add) (None, 7, 7, 2048) 0 ['conv5_block2_out[0][0]',
'conv5_block3_3_bn[0][0]']
conv5_block3_out (Activation) (None, 7, 7, 2048) 0 ['conv5_block3_add[0][0]']
==================================================================================================
Total params: 23,587,712
Trainable params: 0
Non-trainable params: 23,587,712
__________________________________________________________________________________________________
Add classification layer
In order to perform the prediction task, the 772048 blocks of features has to be convert to a single prediction. This can be done by first add a average pooling 2D layer to convert the 772048 features to a single vector with 2048 elements, then apply a dense layer to convert these features into a single prediction per image. The raw prediction value will be the output of the model, the positive number predict class 1, negative number predict class 0.
1
2
3
4
5
6
7
8
#add classification layer on top of the base model to train our dataset
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
print("feature extracted: ", feature_batch.shape)
feature_batch_average = global_average_layer(feature_batch)
print("feature after average layer: ", feature_batch_average.shape)
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print("feature after dense: ", prediction_batch.shape)
1
2
3
feature extracted: (32, 7, 7, 2048)
feature after average layer: (32, 2048)
feature after dense: (32, 1)
Connect the model
Build a new model for the classification task by connecting the preprocessing layer, (the data augmentaion layer as an option), the base_model, and classficiation layers.
In order to perform fine-tuning in the latter step, since our base model contains BatchNormalization layers, it is important to freeze the layer by setting training = False, during the fine-tuning step to aviod non-trainable weights to destory the knowledge of the model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#connect the layers with base model
#input->data augmentation layer(optinonal)->preprocess layer->base model(without top)
#->average pooling layer->Dense 1D layer(prediction)->output
inputs = tf.keras.Input(shape=IMG_SHAPE)
x = inputs
#here, we didn't use the data augmentation step
#x = data_augmentation(inputs)
x = preprocess_input(x)
#The base model contains BatchNormalization layer, needed to be freezed in the trainning process
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
Compile the Model
Before training the model, the model has to be compiled. The optimizer we used is Adam, with learning rate equals to 0.0001. The loss function we used is binary crossentropy because we are dealing with two classes classification, with from_logits=True, because the output of the model is linear.
1
2
3
4
5
6
#compile the model
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
tf.__operators__.getitem (S (None, 224, 224, 3) 0
licingOpLambda)
tf.nn.bias_add (TFOpLambda) (None, 224, 224, 3) 0
resnet50 (Functional) (None, 7, 7, 2048) 23587712
global_average_pooling2d (G (None, 2048) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 2048) 0
dense (Dense) (None, 1) 2049
=================================================================
Total params: 23,589,761
Trainable params: 2,049
Non-trainable params: 23,587,712
_________________________________________________________________
Train the Model
The model will reach approximately 90% accuracy on validation dataset after 30 epoches. The model’s train loss is 0.2691 and train accuracy is 0.9122. For the validation loss is 0.2502 and validation accuracy is 0.9062
1
2
3
4
5
#train model until get 80% accuracy for validation dataset
initial_epochs = 30
loss0, accuracy0 = model.evaluate(validation_dataset)
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
1
2
3
2/2 [==============================] - 3s 93ms/step - loss: 0.6686 - accuracy: 0.5312
initial loss: 0.67
initial accuracy: 0.53
1
2
3
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
Epoch 1/30
10/10 [==============================] - 5s 208ms/step - loss: 0.6526 - accuracy: 0.6081 - val_loss: 0.6622 - val_accuracy: 0.5625
Epoch 2/30
10/10 [==============================] - 2s 164ms/step - loss: 0.6865 - accuracy: 0.5777 - val_loss: 0.5727 - val_accuracy: 0.5938
Epoch 3/30
10/10 [==============================] - 2s 163ms/step - loss: 0.6350 - accuracy: 0.6115 - val_loss: 0.4946 - val_accuracy: 0.7656
Epoch 4/30
10/10 [==============================] - 2s 165ms/step - loss: 0.5700 - accuracy: 0.6757 - val_loss: 0.5301 - val_accuracy: 0.7344
Epoch 5/30
10/10 [==============================] - 2s 164ms/step - loss: 0.5833 - accuracy: 0.6689 - val_loss: 0.5904 - val_accuracy: 0.6094
Epoch 6/30
10/10 [==============================] - 2s 164ms/step - loss: 0.5633 - accuracy: 0.6655 - val_loss: 0.5028 - val_accuracy: 0.6719
Epoch 7/30
10/10 [==============================] - 2s 163ms/step - loss: 0.5220 - accuracy: 0.6993 - val_loss: 0.4518 - val_accuracy: 0.7812
Epoch 8/30
10/10 [==============================] - 2s 164ms/step - loss: 0.4983 - accuracy: 0.7095 - val_loss: 0.4269 - val_accuracy: 0.7812
Epoch 9/30
10/10 [==============================] - 2s 166ms/step - loss: 0.4650 - accuracy: 0.7466 - val_loss: 0.4626 - val_accuracy: 0.7031
Epoch 10/30
10/10 [==============================] - 2s 165ms/step - loss: 0.4773 - accuracy: 0.7399 - val_loss: 0.4236 - val_accuracy: 0.7812
Epoch 11/30
10/10 [==============================] - 3s 229ms/step - loss: 0.4382 - accuracy: 0.7770 - val_loss: 0.3895 - val_accuracy: 0.8125
Epoch 12/30
10/10 [==============================] - 2s 167ms/step - loss: 0.4280 - accuracy: 0.7703 - val_loss: 0.4166 - val_accuracy: 0.8594
Epoch 13/30
10/10 [==============================] - 2s 165ms/step - loss: 0.3893 - accuracy: 0.8176 - val_loss: 0.3135 - val_accuracy: 0.9219
Epoch 14/30
10/10 [==============================] - 2s 162ms/step - loss: 0.4067 - accuracy: 0.7872 - val_loss: 0.3374 - val_accuracy: 0.8750
Epoch 15/30
10/10 [==============================] - 2s 164ms/step - loss: 0.3876 - accuracy: 0.8041 - val_loss: 0.3294 - val_accuracy: 0.9062
Epoch 16/30
10/10 [==============================] - 2s 166ms/step - loss: 0.3630 - accuracy: 0.8378 - val_loss: 0.3480 - val_accuracy: 0.7969
Epoch 17/30
10/10 [==============================] - 2s 164ms/step - loss: 0.3430 - accuracy: 0.8615 - val_loss: 0.2949 - val_accuracy: 0.9375
Epoch 18/30
10/10 [==============================] - 3s 180ms/step - loss: 0.3618 - accuracy: 0.8209 - val_loss: 0.2876 - val_accuracy: 0.9531
Epoch 19/30
10/10 [==============================] - 3s 162ms/step - loss: 0.3300 - accuracy: 0.8480 - val_loss: 0.2808 - val_accuracy: 0.8906
Epoch 20/30
10/10 [==============================] - 2s 165ms/step - loss: 0.3163 - accuracy: 0.8716 - val_loss: 0.3115 - val_accuracy: 0.8906
Epoch 21/30
10/10 [==============================] - 2s 163ms/step - loss: 0.3254 - accuracy: 0.8851 - val_loss: 0.2884 - val_accuracy: 0.9375
Epoch 22/30
10/10 [==============================] - 2s 164ms/step - loss: 0.3067 - accuracy: 0.8919 - val_loss: 0.2604 - val_accuracy: 0.9219
Epoch 23/30
10/10 [==============================] - 2s 166ms/step - loss: 0.3052 - accuracy: 0.8986 - val_loss: 0.2277 - val_accuracy: 0.9688
Epoch 24/30
10/10 [==============================] - 2s 168ms/step - loss: 0.2866 - accuracy: 0.8716 - val_loss: 0.2730 - val_accuracy: 0.9062
Epoch 25/30
10/10 [==============================] - 2s 165ms/step - loss: 0.2824 - accuracy: 0.9054 - val_loss: 0.2647 - val_accuracy: 0.9219
Epoch 26/30
10/10 [==============================] - 2s 164ms/step - loss: 0.2776 - accuracy: 0.8818 - val_loss: 0.2575 - val_accuracy: 0.9062
Epoch 27/30
10/10 [==============================] - 2s 167ms/step - loss: 0.2533 - accuracy: 0.9088 - val_loss: 0.2338 - val_accuracy: 0.8906
Epoch 28/30
10/10 [==============================] - 2s 164ms/step - loss: 0.2690 - accuracy: 0.8953 - val_loss: 0.2692 - val_accuracy: 0.8750
Epoch 29/30
10/10 [==============================] - 2s 163ms/step - loss: 0.2684 - accuracy: 0.8953 - val_loss: 0.1831 - val_accuracy: 0.9531
Epoch 30/30
10/10 [==============================] - 2s 165ms/step - loss: 0.2564 - accuracy: 0.9020 - val_loss: 0.2330 - val_accuracy: 0.9062
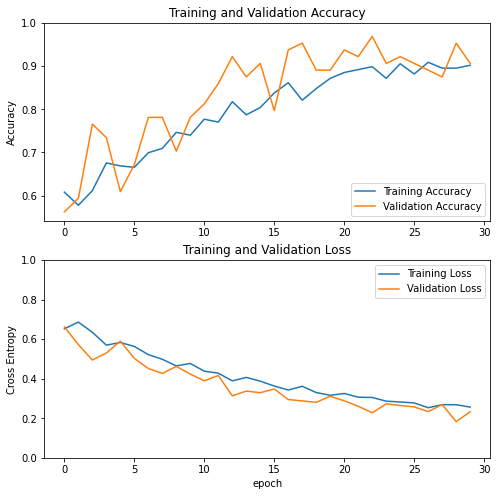
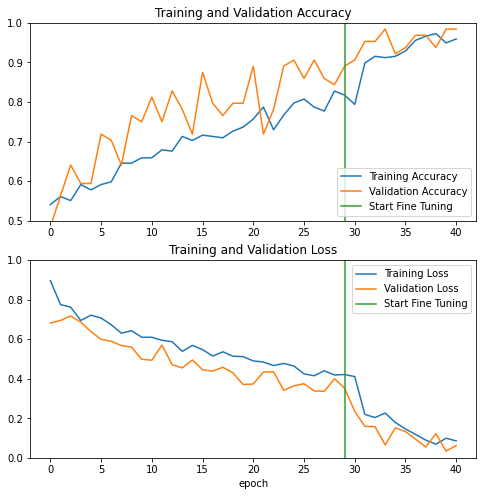
Learning Curve
The learning curves of the training and validation accuracy/loss when using the ResNet50 base model as a fixed feature extractor.
The learning Curve is not as smooth as the tutorial, but still can observe the trend of the accuracy and loss. For the accuracy after each epoch the accuracy will be higher, and for the loss after each epoch the loss will be lower.
As for the difference between train dataset and validation dataset, the validatation dataset shows higher accuracy and lower loss, this is because the tf.keras.layers.BatchNormalization and tf.keras.layers.Dropout affect the accuracy during training. They are turned off when calculating validation loss.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#draw the learning curve
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.savefig('learning_curve_feature_extraction.png')
plt.show()
Fine Tuning
During the feature extraction step, the base model was served as a feature extractor, no parameters or weights were updated during the trianing process. It is also practical to do fine-tuning on the base model which can increase the performance even further.
The fine-tune can be done by unfreeze a small number of top layers of the base model and retrain the model using the dataset. This can force the weights to be adapted from the generic feature maps pre-trained on the large image dataset to the more specific feature maps associated with the camels and horses.
The reason for only fine-tune on the top layers is the features in these layers are more specific to the dataset than the lower layers.
Important notes:
- The fine-tune can only be done after trained the new classification layer with the base model freezed. Otherwise, to train a classification layer from random weights will cause the gradient magnitue increased and will let the base model forget what it learned.
- Fine-tuning should be done with a lower learning rate to avoid overfitting
Unfreeze Top layer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#unfreeze the base model
base_model.trainable = True
#print the number of layers in the base model
print("base model layers: ", len(base_model.layers))
# select the layers to be fine-tune
fine_tune_at = 100
# Freeze other layers
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
#fine tune should be done using a lower learning rate to avoid overfitting
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
# note that the trainable parameters changed
model.summary()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
base model layers: 175
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
tf.__operators__.getitem (S (None, 224, 224, 3) 0
licingOpLambda)
tf.nn.bias_add (TFOpLambda) (None, 224, 224, 3) 0
resnet50 (Functional) (None, 7, 7, 2048) 23587712
global_average_pooling2d (G (None, 2048) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 2048) 0
dense (Dense) (None, 1) 2049
=================================================================
Total params: 23,589,761
Trainable params: 19,454,977
Non-trainable params: 4,134,784
_________________________________________________________________
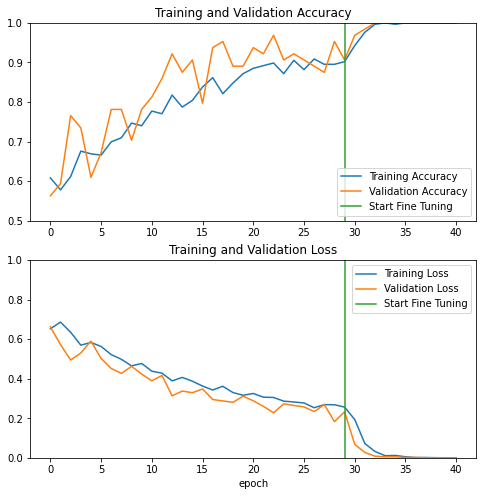
Continue Training
Here we fine tune 10 epochs. The accuracy of the validation dataset increased to 1 from the very beginning steps of the fine-tuning process, and the accuracy of the train dataset increased to 1 from the 4th epoch.
1
2
3
4
5
6
7
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Epoch 30/40
10/10 [==============================] - 10s 368ms/step - loss: 0.1937 - accuracy: 0.9426 - val_loss: 0.0682 - val_accuracy: 0.9688
Epoch 31/40
10/10 [==============================] - 3s 238ms/step - loss: 0.0721 - accuracy: 0.9764 - val_loss: 0.0269 - val_accuracy: 0.9844
Epoch 32/40
10/10 [==============================] - 3s 237ms/step - loss: 0.0320 - accuracy: 0.9966 - val_loss: 0.0082 - val_accuracy: 1.0000
Epoch 33/40
10/10 [==============================] - 3s 236ms/step - loss: 0.0106 - accuracy: 1.0000 - val_loss: 0.0053 - val_accuracy: 1.0000
Epoch 34/40
10/10 [==============================] - 3s 234ms/step - loss: 0.0119 - accuracy: 0.9966 - val_loss: 0.0050 - val_accuracy: 1.0000
Epoch 35/40
10/10 [==============================] - 3s 236ms/step - loss: 0.0052 - accuracy: 1.0000 - val_loss: 0.0018 - val_accuracy: 1.0000
Epoch 36/40
10/10 [==============================] - 3s 239ms/step - loss: 0.0014 - accuracy: 1.0000 - val_loss: 0.0017 - val_accuracy: 1.0000
Epoch 37/40
10/10 [==============================] - 3s 235ms/step - loss: 0.0015 - accuracy: 1.0000 - val_loss: 3.1148e-04 - val_accuracy: 1.0000
Epoch 38/40
10/10 [==============================] - 3s 237ms/step - loss: 4.8445e-04 - accuracy: 1.0000 - val_loss: 1.0168e-04 - val_accuracy: 1.0000
Epoch 39/40
10/10 [==============================] - 3s 238ms/step - loss: 2.3565e-04 - accuracy: 1.0000 - val_loss: 8.9607e-05 - val_accuracy: 1.0000
Epoch 40/40
10/10 [==============================] - 3s 237ms/step - loss: 1.8288e-04 - accuracy: 1.0000 - val_loss: 1.9273e-05 - val_accuracy: 1.0000
Learing Curve
According to the learing curve, after fine tuning the performance of the model increased significatlly.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#visualize the learning curve
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.5, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.savefig('learning_curve_fine_tuning.png')
plt.show()
Evaluation
Accuracy
Test the performance of the model on the test dataset. The model get 0.9250 accuracy on the test dataset.
1
2
3
#evaluate on test dataset
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
1
2
2/2 [==============================] - 0s 48ms/step - loss: 0.3859 - accuracy: 0.8750
Test accuracy : 0.875
Prediction
Predict on the test datset.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
test_image = np.empty((0,224,224,3))
test_label = []
predictions = []
for element in test_dataset.as_numpy_iterator():
# Retrieve a batch of images from the test set
image_batch, label_batch = element
batch_predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
batch_predictions = tf.nn.sigmoid(batch_predictions)
batch_predictions = tf.where(batch_predictions < 0.5, 0, 1)
test_image = np.concatenate((test_image, image_batch), axis=0)
print(image_batch.shape)
#est_image += image_batch
test_label += label_batch.tolist()
predictions += batch_predictions.numpy().tolist()
print(len(predictions))
print('Predictions:\n', predictions)
print('Labels:\n', test_label)
1
2
3
4
5
6
7
(32, 224, 224, 3)
(8, 224, 224, 3)
40
Predictions:
[1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Labels:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
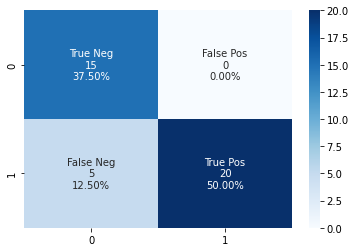
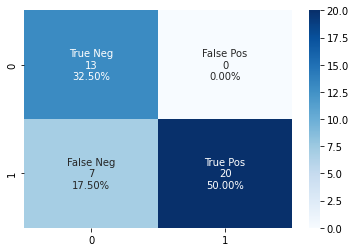
Confusion Matrix
1
2
cf_matrix = tf.math.confusion_matrix(predictions,test_label)
print(cf_matrix)
1
2
3
tf.Tensor(
[[15 0]
[ 5 20]], shape=(2, 2), dtype=int32)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
cf_matrix = tf.math.confusion_matrix(predictions,test_label)
group_counts = cf_matrix.numpy().flatten().tolist()
print(group_counts)
group_names = ['True Neg','False Pos','False Neg','True Pos']
print(group_names)
group_percentages = ["{0:.2%}".format(value) for value in
cf_matrix.numpy().flatten()/np.sum(cf_matrix)]
labels = [f"{v1}\n{v2}\n{v3}" for v1, v2, v3 in
zip(group_names,group_counts,group_percentages)]
labels = np.asarray(labels).reshape(2,2)
sns_heatmap = sns.heatmap(cf_matrix, annot=labels, fmt='', cmap='Blues')
fig = sns_heatmap.get_figure()
fig.savefig("confusion_matrix.png")
1
2
[15, 0, 5, 20]
['True Neg', 'False Pos', 'False Neg', 'True Pos']
Wrong Pediction
1
2
3
4
wrong_prediction = [idx for idx, elem in enumerate(predictions)
if elem != test_label[idx]]
print("wrong predict number: ",len(wrong_prediction))
print("wrong predict index: ", wrong_prediction)
1
2
wrong predict number: 5
wrong predict index: [0, 1, 2, 6, 7]
1
2
3
4
5
6
7
8
9
plt.figure(figsize=(10, 10))
count = 1
for i in wrong_prediction:
#print(str(predictions[i]) + " " + str(test_label[i]))
ax = plt.subplot(len(wrong_prediction)//3+1, 3, count)
plt.imshow(test_image[i].astype("uint8"))
plt.title(class_names[predictions[i]] + ":" + class_names[test_label[i]])
plt.axis("off")
count+=1

1
2
3
4
5
6
7
8
9
#check if test dataset is correct
#plt.figure(figsize=(10, 10))
#count = 1
#for i in range(40):
# ax = plt.subplot(4, 10, count)
# plt.imshow(test_image[i].astype("uint8"))
# plt.title(class_names[test_label[i]])
# plt.axis("off")
# count+=1
More Results
Results with data augmentation
Model Architecture
The model with data augmentaion contains a sequential layer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 224, 224, 3)] 0
sequential (Sequential) (None, 224, 224, 3) 0
tf.__operators__.getitem (S (None, 224, 224, 3) 0
licingOpLambda)
tf.nn.bias_add (TFOpLambda) (None, 224, 224, 3) 0
resnet50 (Functional) (None, 7, 7, 2048) 23587712
global_average_pooling2d (G (None, 2048) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 2048) 0
dense (Dense) (None, 1) 2049
=================================================================
Total params: 23,589,761
Trainable params: 19,454,977
Non-trainable params: 4,134,784
This is formatted as code
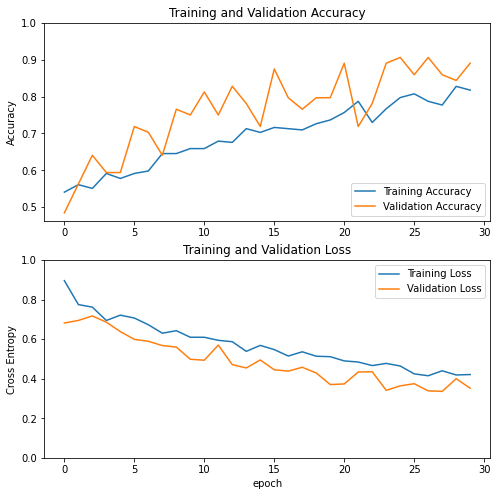
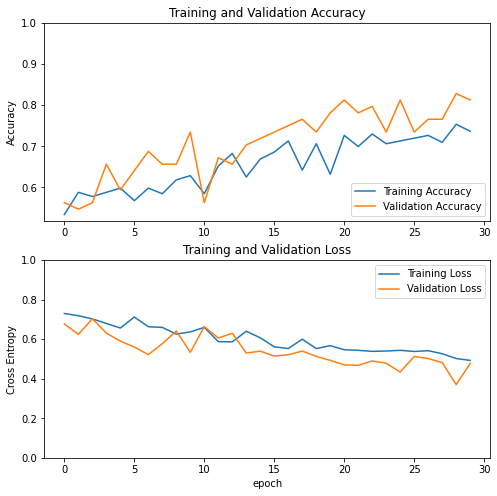
Learning Curve for feature extraction
After 30 epoches of feature extraction training,
1
loss: 0.4212 - accuracy: 0.8176 - val_loss: 0.3520 - val_accuracy: 0.8906
Learning Curve for fine-tuning
After 10 epoches of fine-tuning, the model
1
loss: 0.0854 - accuracy: 0.9595 - val_loss: 0.0624 - val_accuracy: 0.9844
Wrong prediction

Confusion Matrix
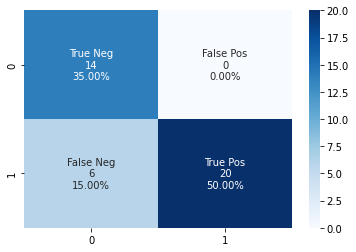
Results with data augmentaion, without preprocessing
Model Architecture
The model with data augmentation contains sequential layer, without preprocessing layers (slicing, TF)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_3 (InputLayer) [(None, 224, 224, 3)] 0
sequential (Sequential) (None, 224, 224, 3) 0
resnet50 (Functional) (None, 7, 7, 2048) 23587712
global_average_pooling2d (G (None, 2048) 0
lobalAveragePooling2D)
dropout_1 (Dropout) (None, 2048) 0
dense (Dense) (None, 1) 2049
=================================================================
Total params: 23,589,761
Trainable params: 19,454,977
Non-trainable params: 4,134,784
# This is formatted as code
Learning Curve for feature extraction
The model after training for feature extraction:
1
loss: 0.4927 - accuracy: 0.7365 - val_loss: 0.4773 - val_accuracy: 0.8125
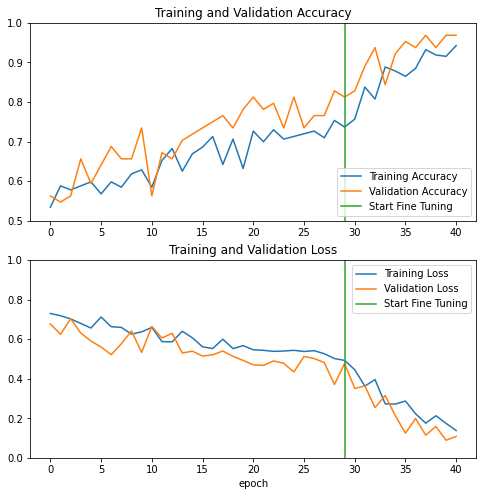
Learning Curve for fine-tuning
The model performance after fine-tuning
1
loss: 0.1380 - accuracy: 0.9426 - val_loss: 0.1083 - val_accuracy: 0.9688
Wrong prediction

Confusion Matrix
1
!pip freeze > requirements.txt